A brief overview of OpenEBS
We shall use OpenEBS as the de-facto storage engine for our Microk8s cluster. This choice is backed by 3 decisions:
- OpenEBS is the largest and most active open source project in the Kubernetes storage ecosystem. It is backed by a big community.
- OpenEBS is vendor agnostic. Whatever principles apply to Microk8s also apply to GKE and AKS, for instance.
- OpenEBS gives a plethora of options for storage. Different workloads have different storage needs and OpenEBS can be configured to cater all these needs, within the same cluster.
Before we dive into OpenEBS, let’s explore the concept of Container Attached Storage(CAS). This is the cornerstone principle of OpenEBS.
Persistent Volumes in Kubernetes are typically storage blobs which are attached to a workload. This approach doesn’t abstract out the underlying storage solution. CAS is designed specifically to decouple this. Team A might want a write-optimised storage solution, whereas Team B would need a read-heavy storage solution. CAS abstracts out the actual storage implementation from the storage needs. Both teams can have their storage needs met without migrating from one storage solution to another. How does CAS achieve this?
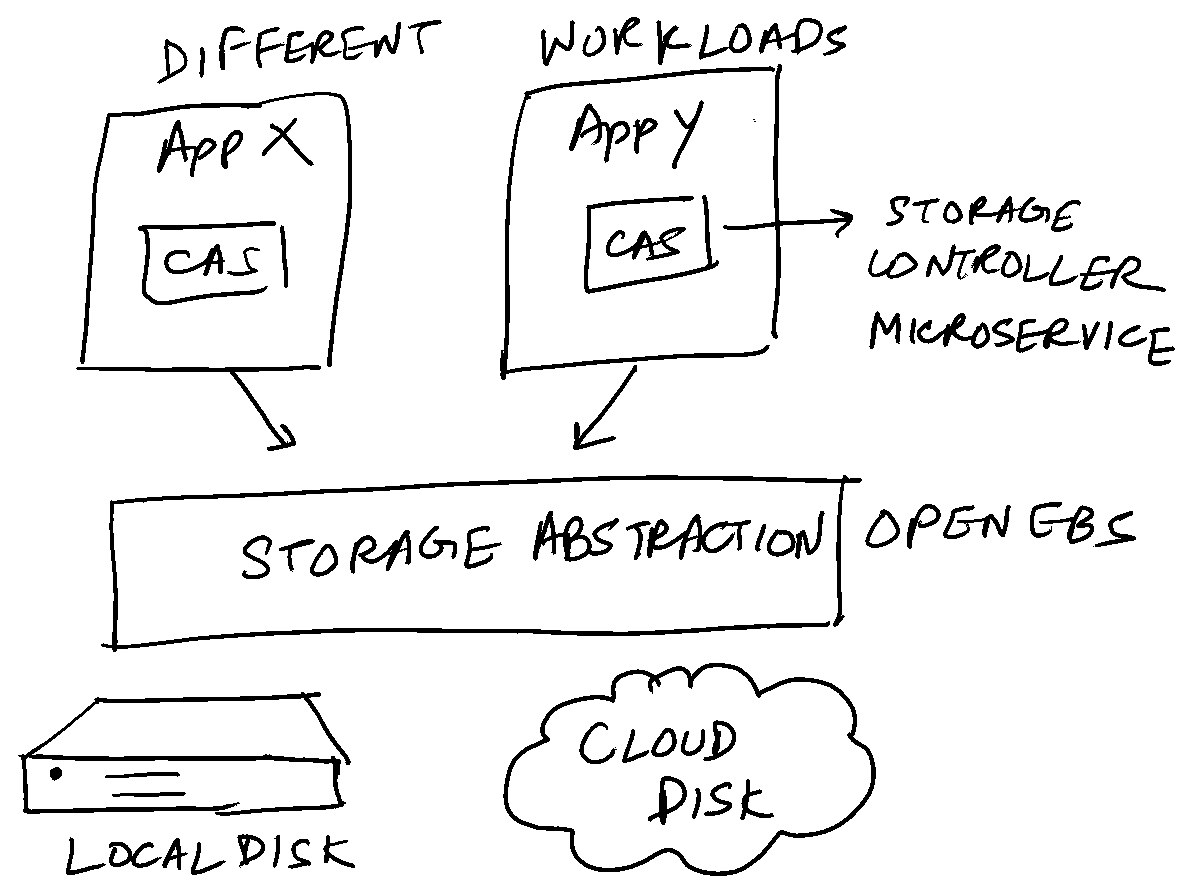
Every persistent volume in the cluster is backed by a controller microservice. Hence the name Container “attached” storage. This allows controlling of storage policies on a granular scale, like a per volume basis. The controller attached with the storage can be tweaked and tuned to the specified storage policy. In the storage needs example above, this would entail Team A creating a storage class on top of OpenEBS fine-tuned for their needs, and similarly for Team B.
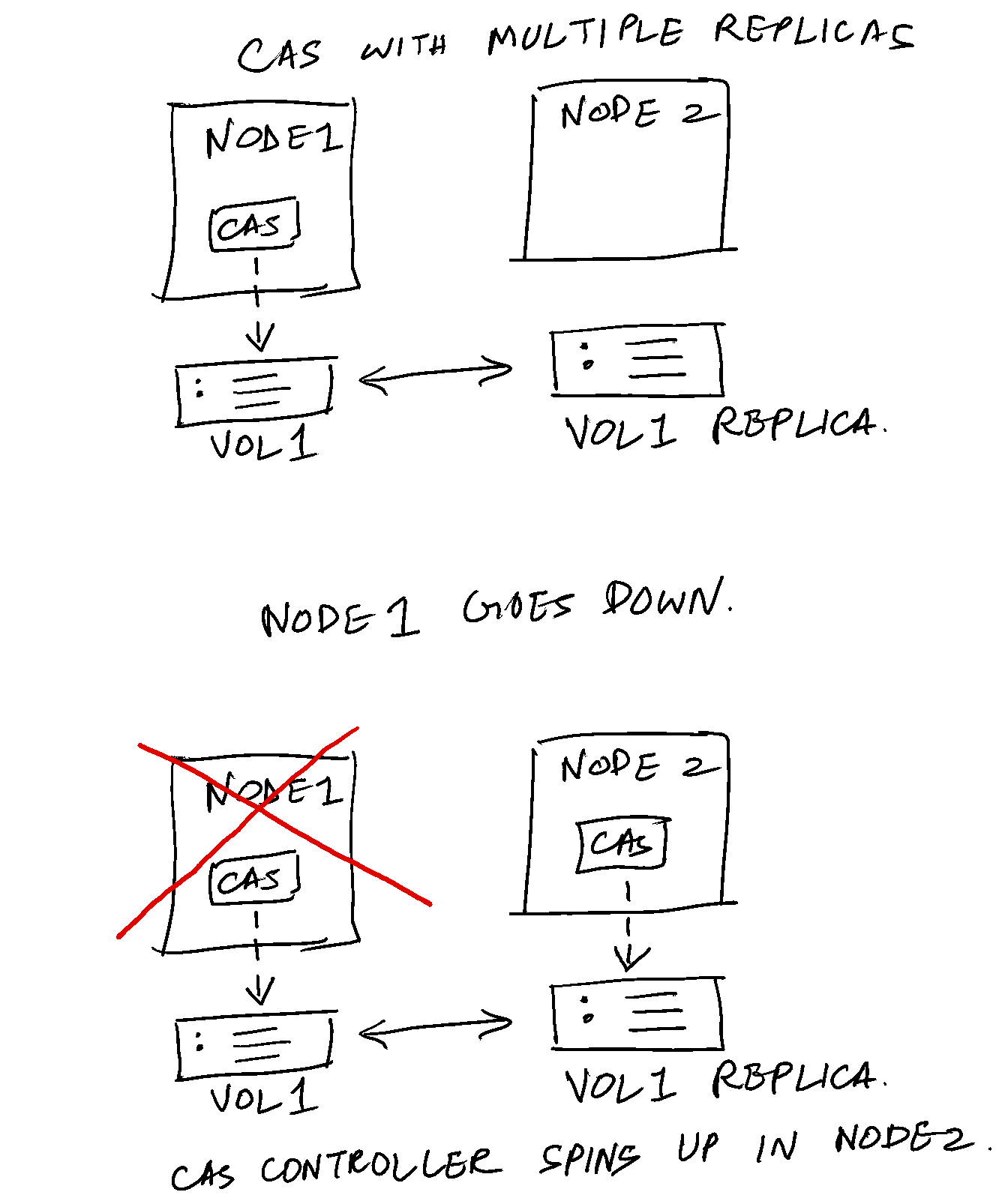
In addition, this architecture promotes higher resiliency. If a node containing a volume v1 goes down, for example, a newer pod can be spun up in a different node which houses a replica of v1.
In many ways, I see OpenEBS as the holy grail of Kubernetes storage. There are 3 classes of storage offered by OpenEBS which will meet most of the needs of Kubernetes workloads. In the increasing order of sophistication, these are:
Local storage #
These are the volumes and the disk space in the respective nodes. This is suited for the following scenarios:
- Workloads which can manage availability and scalability all by themselves. Ex: Stackgres Postgres operator.
- Workloads where disk I/O performance is critical. Not surprisingly, most workloads in category above also belong to this category.
- Short lived stateful workloads where persistence isn’t necessary. Ex: machine learning use cases.
- We’re only running a single node cluster.
Again, there are many flavours of local storage engines. We will do a deep dive in a later post.
Jiva #
Jiva belongs to the class of “replicated engines”. Data is synchronously replicated to different nodes in the cluster. This provides insurance against node failure. This class of storage is your typical classic Kubernetes storage engine. You would use this for most of your storage needs.
Cstor #
Jiva is pretty useful for most storage needs. But what if you need features like volume snapshots, volume expansion and volume cloning? This is where cstor is useful. Think of Cstor as beefed up version of Jiva.
We shall look at how to set all the 3 storage engines on our Microk8s cluster in the next post.